安装
1 | yum install -y centos-release-gluster |
启动 glusterFS
1 | systemctl start glusterd.service |
创建存储目录
1 | mkdir -p /data/gluster/data |
创建挂接目录
1 | mkdir g_kaldi_train |
配置节点,任何一台机器,建议非当前机器
1 | gluster peer probe <ip/hostname> |
A)新增节点,任何一台机器,建议非当前机器
1 | gluster volume create kaldi-train server1:/exp1 server2:/exp2 |
B)扩容节点,任何一台机器,建议非当前机器
1 | gluster volume add-brick kaldi-train 172.23.0.14:/data/gluster/data |
启动volume
1 | gluster volume start models |
挂接到机器路径
1 | mount -t glusterfs 172.23.0.32:kaldi-train g_kaldi_train |
移除挂接
1 | sudo fusermount-glusterfs -uz /data/app/asr_data |
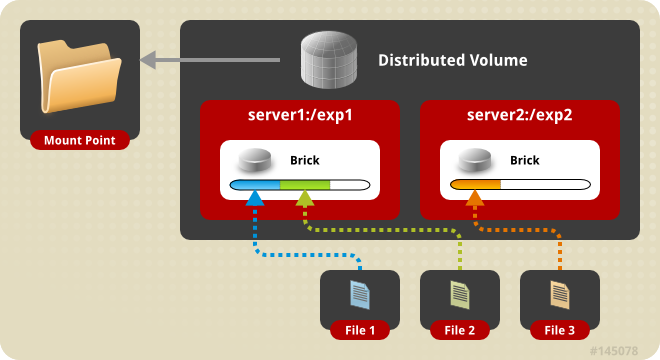
官方推荐volume使用的5种方式:
1、默认模式,既DHT, 也叫 分布卷: 将文件已hash算法随机分布到一台服务器节点中存储。
1 | gluster volume create test-volume server1:/exp1 server2:/exp2 |
2、复制模式,既AFR, 创建volume 时带 replica x 数量: 将文件复制到 replica x 个节点中。
1 | gluster volume create test-volume replica 2 transport tcp server1:/exp1 server2:/exp2 |
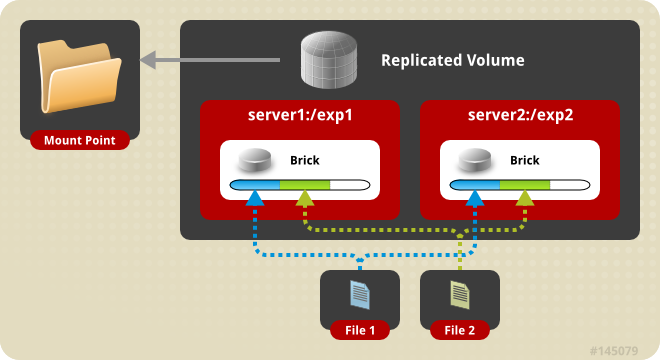
3、条带模式,既Striped, 创建volume 时带 stripe x 数量: 将文件切割成数据块,分别存储到 stripe x 个节点中 ( 类似raid 0 )。
1 | gluster volume create test-volume stripe 2 transport tcp server1:/exp1 server2:/exp2 |
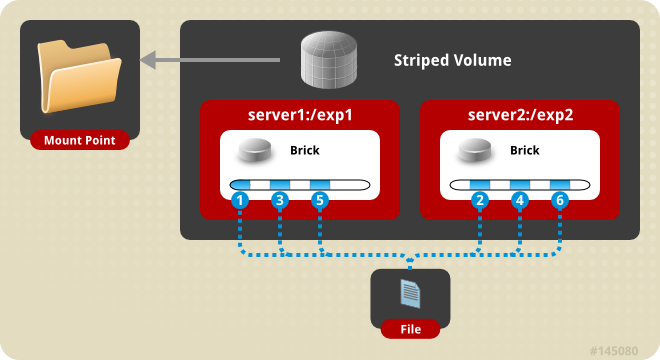
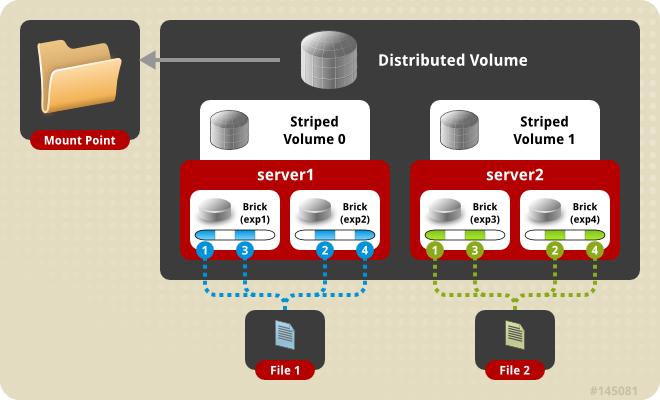
4、分布式条带模式(组合型),最少需要4台服务器才能创建。 创建volume 时 stripe 2 server = 4 个节点: 是DHT 与 Striped 的组合型。
1 | gluster volume create test-volume stripe 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 |
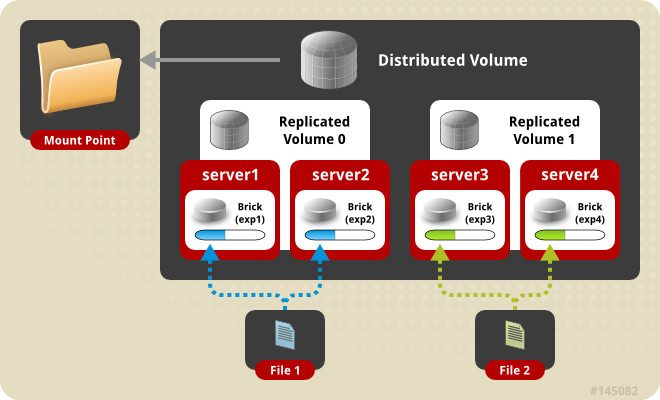
5、分布式复制模式(组合型), 最少需要4台服务器才能创建。 创建volume 时 replica 2 server = 4 个节点:是DHT 与 AFR 的组合型。
1 | gluster volume create test-volume replica 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 |
其他问题
- 创建volume失败,再重新创建会报volume存在,处理办法:
1
2
3在/data/gluster/data目录中删除".glusterfs"的目录
rm -rf /data/gluster/data/.glusterfs
sudo setfattr -x trusted.glusterfs.volume-id /data/gluster/data
参数优化
(k8s-volume 为 volume 名称)
# 开启 指定 volume 的配额
$ gluster volume quota k8s-volume enable
# 限制 指定 volume 的配额
$ gluster volume quota k8s-volume limit-usage / 1TB
# 设置 cache 大小, 默认32MB
$ gluster volume set k8s-volume performance.cache-size 4GB
# 设置 io 线程, 太大会导致进程崩溃,可以开到64
$ gluster volume set k8s-volume performance.io-thread-count 16
# 设置 网络检测时间, 默认42s
$ gluster volume set k8s-volume network.ping-timeout 10
# 设置 写缓冲区的大小, 默认1M
$ gluster volume set k8s-volume performance.write-behind-window-size 1024MB
# 开启 异步 , 后台操作,默认打开
$ gluster volume set k8s-volume performance.flush-behind on
# 设置 回写 (写数据时间,先写入缓存内,再写入硬盘),默认打开
$ gluster volume set k8s-volume performance.write-behind on
# 设置server进程数,默认2
$ gluster volume set k8s-volume server.event-threads 4
# 设置client进程数,默认2
$ gluster volume set k8s-volume client.event-threads 4
gluster异常修复
1 | 追查问题,先查看volume的状态 |
1 | 修复方法 |
机器重装系统,gluster补救办法
假设:192.168.50.204是重装机器,192.168.50.197是正常机器
准备工作
保证重装前后的机器host一致,更改hosts和hostname保证一致。
如果修改了hostname,别忘记重启。
第一步:先找到重装机器的uuid
1 | 197机器输入: |
可见204机器状态是peer rejected,而且获取到uuid
第二步:修改重装机器的uuid
1 | sudo vim /var/lib/glusterd/glusterd.info |
第三步:从正常机器同步gluster配置
1 | 通常发现204机器仍然会是peer rejected |
故需要从其他机器同步配置
1 | 在204机器执行 |